Trusting AI Agents, Who Is Acting?
AI agent security is often framed as an identity problem. It is more accurately an execution problem. This article separates five concepts, identity, role, identifier, attestation, authority, and shows why identity-centric security models do not survive contact with agentic systems.
- tags
- #Security #Ai Agents #Agentic #Authz #Authority Continuity #Pic
- published
- reading time
- 10 minutes
AI agent security is usually approached as an identity problem: the question becomes “what is the agent’s identity, and what is it allowed to do?”. This framing is inherited from decades of human-centric and client-centric authorization design, and it works reasonably well as long as the entity being authorized is stable, persistent, and accountable in its own right. AI agents are none of those things in practice, and the framing produces a steady accumulation of edge cases that identity-centric security models keep trying to patch without changing the underlying assumption.
A note on terminology. Throughout this article, AI agent and workload are used interchangeably. The reasoning applies to any executor that participates in a multi-hop execution chain, whether it is an AI agent, a microservice, a serverless function, or a long-running daemon. The structural problem and its solution are the same in all cases.
A more useful question is: which execution is this workload continuing, and under whose authority? Identity remains relevant, but it stops being the center of the model. Execution becomes the center, and identity, role, identifier, attestation, and authority each take a narrower and more precise role around it. The rest of this article works through these five concepts using a deliberately minimal example, then shows why this separation matters for agentic systems.
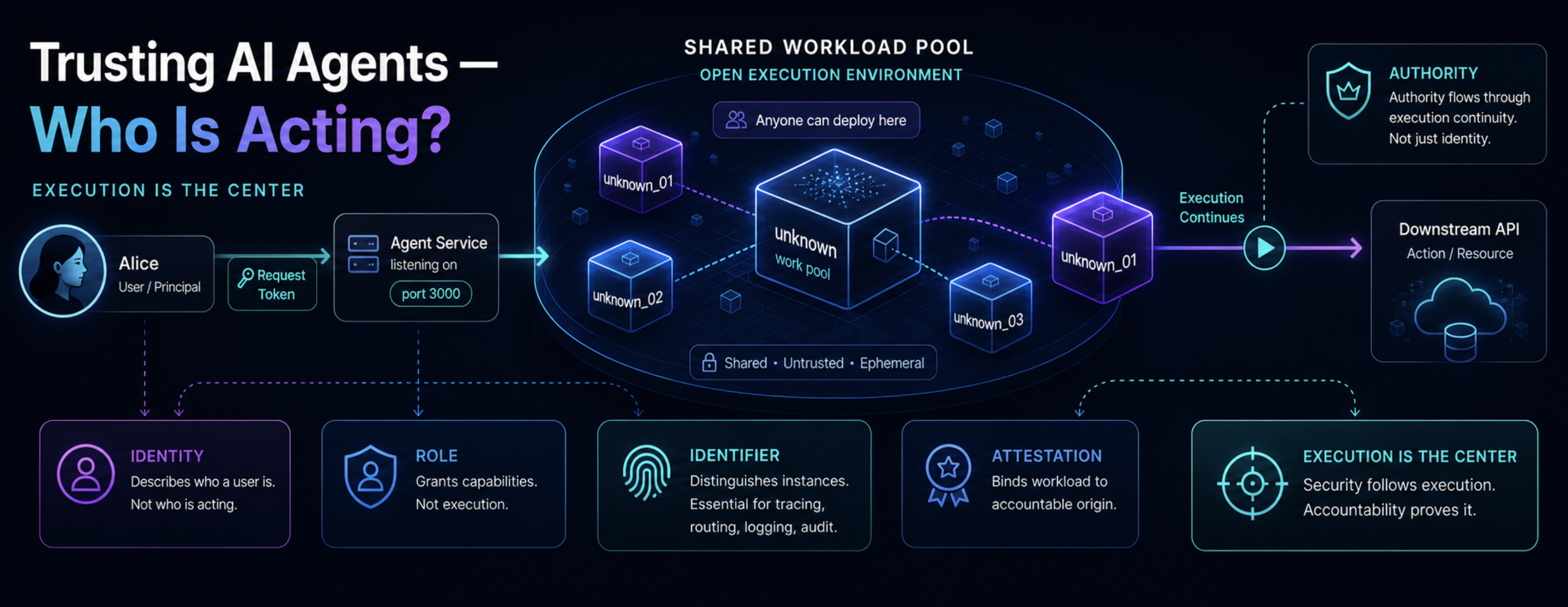
A shared workload pool
Consider a server that anyone can deploy workloads to. There is no perimeter, no trusted operator, no stable ownership, only a shared pool of executors. Someone deploys a service anonymously and makes it listen on port 3000. Call it unknown. Alice connects to unknown and sends a token. unknown receives the token and uses it to call a downstream API on Alice’s behalf.
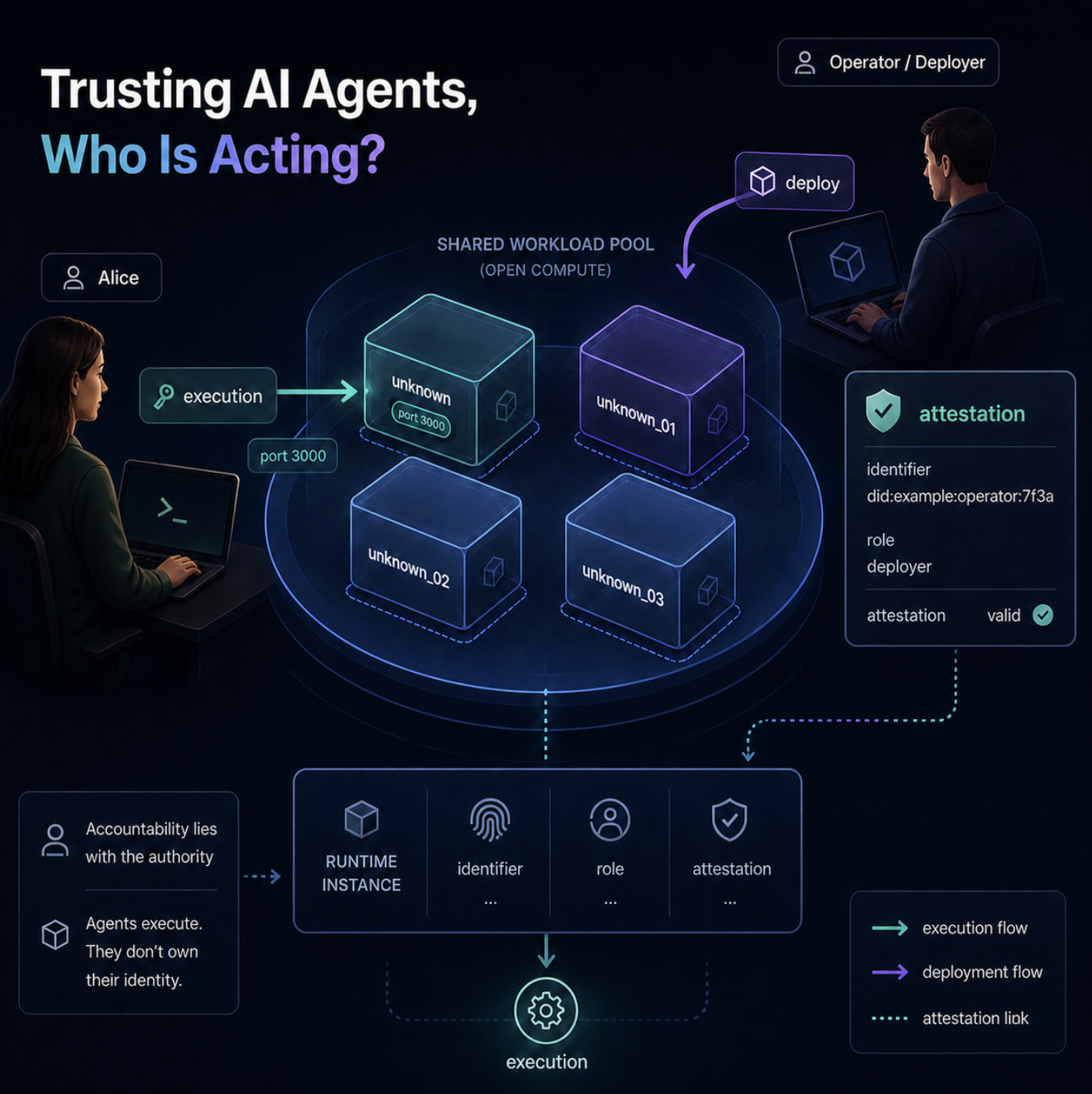
Technically this works. It is also unsafe, and the reason is instructive:
You do not need an identity to impersonate someone. You only need to receive their token and use it.
Most production systems hide this fact behind a perimeter. We do not actually trust the workload, we trust the cloud account, the deployment pipeline, the organization that operates the environment, and the controls layered around it. Strip the perimeter away and the workload is just an executor that needs to demonstrate it is continuing an execution Alice delegated to it. That is not an identity problem, it is an execution problem.
The first principle follows directly:
Continuity carries authority. To carry authority, an executor does not need its own identity. It needs to be a verifiable continuation of the right execution.
Scaling and the role of identifiers
Now scale unknown to three replicas, unknown_01, unknown_02, unknown_03, and eventually to a thousand. Each replica needs a distinct identifier, because tracing, routing, logging, audit, debugging, and attestation all require the ability to point to a specific runtime instance. None of this changes the trust posture of the system. An identifier tells you which instance is acting, it does not tell you whether that instance should be trusted, nor does it create the authority under which the instance acts.
The implementation of identifiers is contextual:
| Technology | Where it fits |
|---|---|
DID | Public or cross-organization boundaries |
SPIFFE | Workload-to-workload inside a service mesh |
IAM role | Inside a single cloud provider |
X.509 / attestation | Binding identifiers to runtime properties |
The model should not depend on any one of these technologies. The choice is engineering, not architecture. What matters is the conceptual role the identifier plays:
An identifier binds a specific runtime instance, and nothing more.
Roles describe capacity
Suppose Alice tightens her requirements: she will only delegate execution to a workload that can prove it is running under the role authorized-workload. This is a meaningful improvement, but it is worth being precise about what a role actually is. A role describes the capacity in which a workload acts, for example Security Monitoring Agent, Backup Worker, Document Summarizer, Payment Processor. It says that a workload is permitted to act in a particular capacity, given some prior authorization.
A role is not an identity. A role cannot be held accountable, cannot sign a contract, cannot own responsibility, cannot be the subject of a legal claim. Confusing roles with identities is one of the recurring sources of authorization bugs in distributed systems, because the role appears to answer the question “who is acting” when in fact it only answers “in what capacity”.
Where accountability actually lives
The accountable party is rarely visible inside the execution itself. A workload running in a cluster may carry no human identity and no direct organizational identity. It may carry only an attestation that says, in effect: “this workload, with this role, was deployed in this environment under these conditions”. If the attestation is verifiable, accountability can be inferred from it: the accountable entity is whoever deployed, authorized, configured, or operates the workload. That entity may be a human, an organization, a system owner, a cloud control plane, a certificate authority, an attestation root, or a legal structure.
This is structurally similar to how trust works on the public web. When you visit www.company-example.com, you do not authenticate every process behind the service. You rely on a certificate, a domain, an organization, and the legal and operational accountability that sits behind them. Workload accountability follows the same pattern:
Responsibility is assigned to an accountable entity. That entity may be represented through identity, certificate, attestation, organizational binding, or legal structure, not necessarily through an identity that appears inside the execution.
This gives the second piece of the model: attestation proves runtime properties, and those properties, combined with the deployment context, are what allow accountability to be inferred when no human or organizational identity is directly carried by the workload.
Continuing authority versus creating it
So far Alice has been the source of authority: she expressed intent, and the workload continued it. The picture changes when a workload initiates an action on its own. If unknown_01 decides to start a new operation without a delegating principal upstream, it is no longer continuing authority. It is creating it.
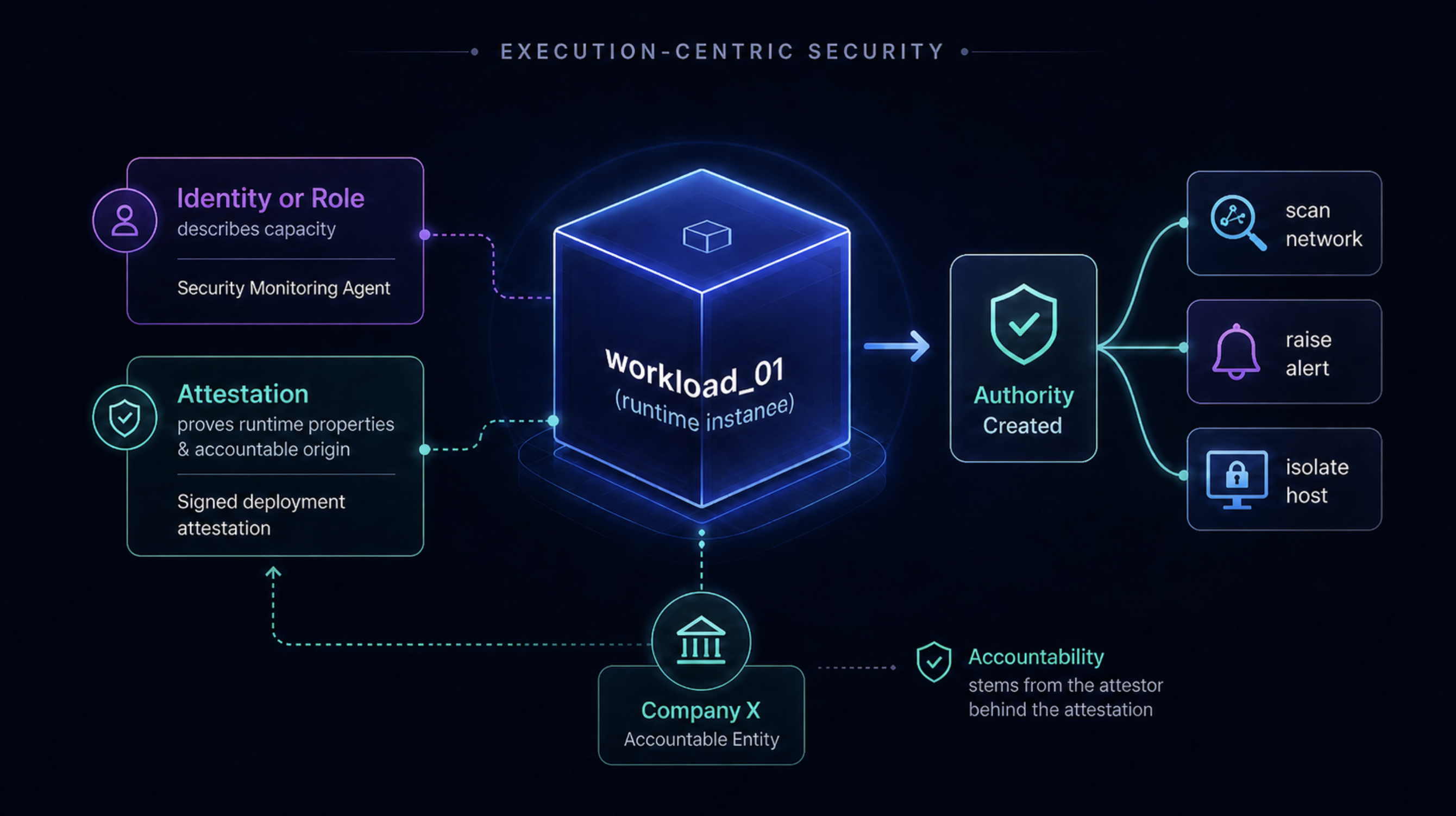
Creating authority requires a root of accountability, because authority is meaningful only when it can be tied back to an entity that can be held responsible for it. A workload may be authorized to create authority because of its role: a Security Monitoring Agent may be permitted to initiate actions like:
scan network
raise alert
isolate host
collect logs
But the role only confers this capacity because the role itself is anchored to an accountable entity, the organization, deployment context, or operator that authorized the role to exist and to act in this capacity.
The general statement is:
Authority can be created from an accountable root, where the root may be an identity, a role anchored to an accountable entity, or an attested deployment context.
No human identity needs to be present inside the execution for this to work. What matters is that the chain of accountability can be reconstructed from what is verifiable.
The five-way separation
Once these distinctions are explicit, the model collapses to a small set of orthogonal concepts:
- Identity anchors responsibility. It identifies who is accountable.
- Role describes capacity. It identifies the mandate under which a workload acts.
- Identifier binds the runtime instance. It is useful for tracing, routing, logging, and audit.
- Attestation proves runtime properties. It allows accountability to be inferred when identity is not directly carried.
- Authority is what may be done in a given execution. It is created from an accountable root and carried forward by continuity.
Each of these can be implemented with different technologies, evolved independently, and reasoned about separately. Conflating any two of them, most commonly identity and identifier, or identity and authority, is what produces the recurring confused deputy and privilege escalation patterns in distributed and agentic systems.
Why identity-centric models break
An AI agent does not always need its own identity. If the agent is creating authority, it needs a root of accountability, but that root does not have to be the agent itself, and in most realistic deployments it is not. If the agent is continuing authority created by someone else, it does not need to become that identity at all. It needs to prove that it is the right executor, in the right role, with the right runtime properties, inside the right execution.
Identity-centric models try to make identity carry all of these responsibilities at once:
accountability
routing
runtime instance binding
authorization scope
delegation semantics
execution continuity
The model holds together while the underlying system is stable and synchronous, and it begins to fail as soon as workloads become replicated, short-lived, re-keyed, or composed into chains that cross trust boundaries. The failure is structural, not implementational. No amount of engineering on the identity layer fixes it, because the wrong concept is being asked to do the work.
Why identity-centric security models struggle with AI agents
Identity-centric security models, broadly construed, are organized around a small set of primitives: a principal, a credential the principal possesses, a set of scopes the credential carries, and a resource that validates the credential at the point of access. The model fits well when there is a single user, a single client, and a bounded set of resources to authorize against, and it has been extended in many directions over the years to cover federation, delegation, and short-lived credentials.
AI agents introduce a different shape of problem. Execution moves across tools, services, runtimes, other agents, and trust boundaries, and the relevant security question at each step is no longer “does the caller possess a valid credential?” but “is this step a valid continuation of the execution that was originally authorized?”. Identity-centric models have no native way to represent that continuation. Sender-constrained tokens, holder-of-key bindings, attestation extensions, and similar mechanisms address specific symptoms (replay, token theft, audience confusion) but do not change the underlying assumption that authority is anchored to a possessed artifact rather than to a continued execution.
Proof of Possession can demonstrate that a party currently holds a credential. It cannot, on its own, demonstrate that a given execution is a valid continuation of an earlier authorized one.
That is a different primitive, and it requires modeling the execution itself rather than only the identity attached to it. The point is not that identity-centric models are wrong, they remain useful for the cases they were designed for. The point is that they are incomplete for systems where authority needs to flow through multi-hop execution chains, and the gap is not closed by adding more identity-layer features.
Final principle
AI agent security should not start with “what is the agent’s identity?”. It should start with “which execution is this agent continuing, and under whose authority?”. Identity remains part of the model, it anchors responsibility wherever responsibility needs to be anchored, but it stops being the center.
Execution is the center. Identity, role, identifier, attestation, and authority each do a smaller, more precise job around it, and the system becomes easier to reason about as a result.
It is worth keeping in mind that AI agents are not the source of this problem, they are only making it visible. The same gap exists in any distributed system where workloads are replicated, short-lived, re-keyed, or composed into chains that cross trust boundaries. Microservice meshes, multi-cloud workflows, and workload-to-workload communication inside a single cluster all face the same structural mismatch between an identity-centric authorization model and an execution that moves across multiple hops. Agents simply remove the assumptions, the perimeter, the synchrony, the stable ownership, that previously hid the problem. What breaks under AI agents was already broken in distributed systems, and the fix is the same in both cases.